I paid five dollars to read a Medium article about my own free, open source library. It was sold as hard-won production experience.
It was fabricated.
The first code sample used RubyLLM.client, which does not exist. It called client.chat(messages: ...), which does not exist. Then it invented RubyLLM::StreamInterrupted, RubyLLM::APIError, and a stream: proc API that RubyLLM has never had.
The problem was not merely wrong information. Wrong information can be corrected. This was sold as experience with RubyLLM in production, which is a much more valuable claim.
AI slop is not just filling the web with predictable cadence. It is fabricating experience. It is letting people skip the work, skip the scar tissue, and still write in the voice of someone who has been there.
In open source, that turns into a tax. Maintainers build the thing, write the docs, publish the source, keep the examples working, answer the issues, and then have to police hallucinated articles about their own projects before users start debugging ghosts.
The Four Magic Words in Tech
Production. Scale. Security. Reliability.
In the tech world, attach one of these words to a claim and it immediately becomes true. “This does not scale” can kill a project before anyone measures it. “This is not production ready” can sabotage it without a single deploy.
So when an article says “what broke in production”, it is not just offering advice. It is claiming experience, and experience cannot be hallucinated.
The first version opened by saying the author had spent three weeks on the wrong side of the problem before getting something stable in production. That is a powerful claim. It tells the reader to relax and inherit the author’s scars.
There were no scars. The author had not even run the first example.
This is why fake experience is so dangerous. Bad code fails fast. Fake experience lingers. It gets quoted. It gets summarized. It gets used in meetings by people who do not know enough yet to see the hollow center.
The recipe is familiar. Streaming failures. Token budgets. Provider fallback. Turbo Streams. Redis circuit breakers. nginx buffering. Load testing. They sit near “LLM production” in the LLM training data. Arrange them with enough confidence and the result smells real.
Production experience is not a smell. It is a thing that happened, and none of these things happened.
What Actually Happened
Here is the short version.
Most articles about RubyLLM are good. Since it became popular, I have seen a few confident guides from people who clearly had not run the code. Usually they disappear into LinkedIn or search results. This one made the pattern impossible to ignore.
{kind=link}
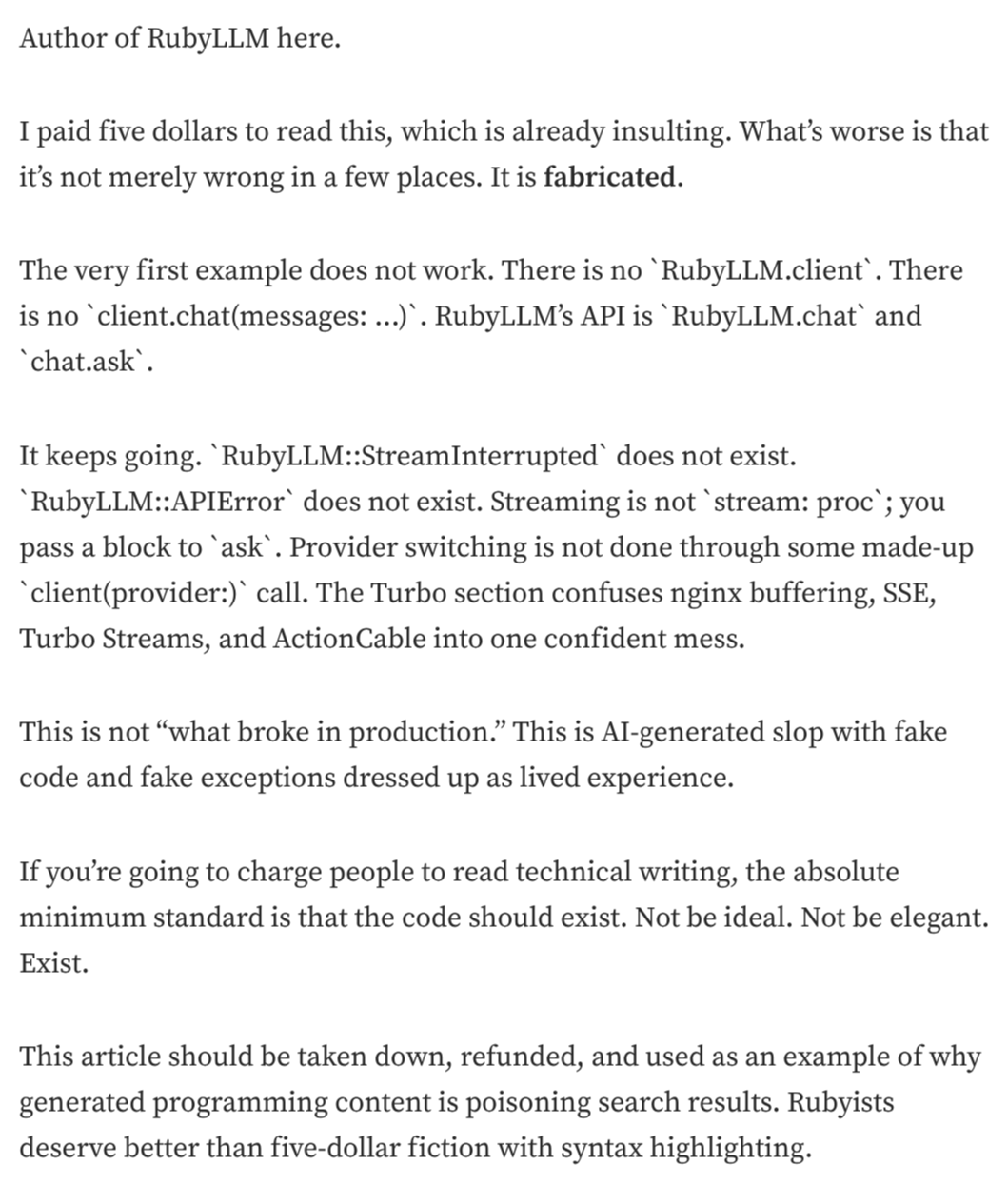
Author of RubyLLM here.
The very first example does not work.
The article is not merely wrong in a few places. It is fabricated.
…
{kind=link}
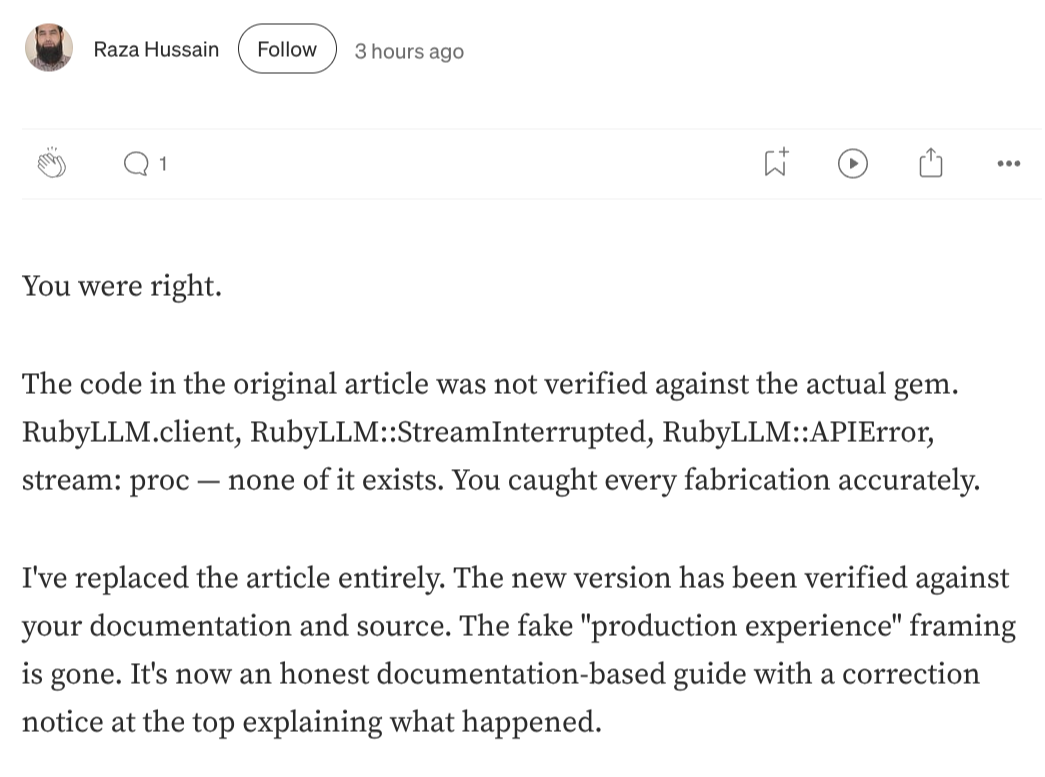
You were right.
The code in the original article was not verified against the actual gem.
RubyLLM.client,RubyLLM::StreamInterrupted,RubyLLM::APIError,stream: proc– none of it exists. You caught every fabrication accurately.I’ve replaced the article entirely. The new version has been verified against your documentation and source. The fake “production experience” framing is gone. It’s now an honest documentation-based guide with a correction notice at the top explaining what happened.
“I’ve replaced the article entirely.”
It was a long article. The completely rewritten replacement appeared in a few minutes. The fake method names were replaced with real ones, but the posture stayed the same: “RubyLLM in production”, “what tutorials skip”, “streaming failures”, “provider fallback”, “token budgets.”
The method names got real. The experience didn’t.
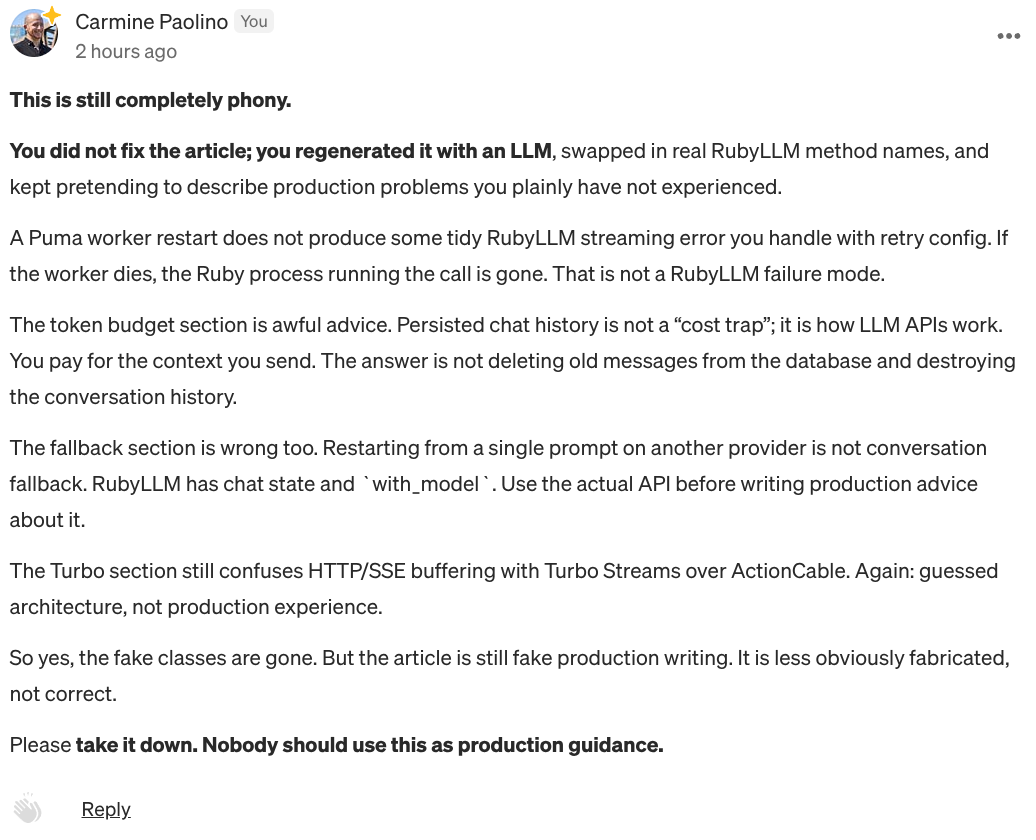
The new version claimed Puma restarts produce neat RubyLLM streaming errors. They do not. If the worker dies, the Ruby process running the call is gone. It suggested deleting old persisted chat messages as context management. That is destroying conversation history. It described fallback by throwing away the chat and asking another provider the last prompt as a fresh question. That is not conversation fallback. It confused HTTP/SSE buffering with Turbo Streams over ActionCable.
Not battle scars. Guesses presented as authority.
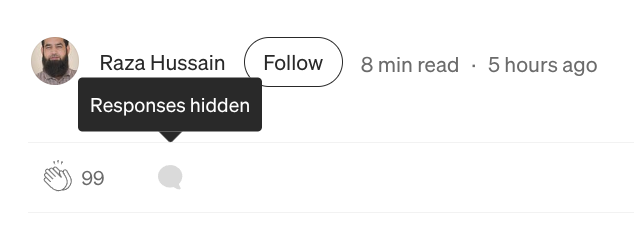
I called the second version what it was: phony. The author then hid responses while keeping the article up.
{kind=link}
{kind=link}
I reported the article to Medium and contacted the publication that promoted it with the fabricated APIs, the author’s admission, and the hidden corrections. To their credit, the editor replied quickly, apologized, and removed it from the publication. But only the author can take down the original Medium article, so the piece remained available without the maintainer corrections visible next to it.
Do Not Counterfeit Experience
Please do write about your favourite software. Critique it too. Tell us maintainers where the API is wrong, the docs are bad, the abstraction leaks. Preferably in an issue so we can actually see it. That feedback is gold.
But do not counterfeit experience. If you’re using The Four Magic Words in Tech, the bar is even higher.
And if you run a technical publication, please at least check the first example.
{kind=link}